
Hugging Faceとは?使い方や実際に試してみた感想を解説!

Hugging Faceとは、世界中のAIモデルやデータセットを誰でも自由に利用・共有できる、世界最大級のオープンソースプラットフォームです。
AI開発の現場や研究、個人の学習と幅広い分野で注目されているHugging Faceですが、「どんなモデルが使えるの?」「無料でどこまでできるの?」「商用利用は本当に安全?」といった疑問や不安がある方もいるはずです。
本記事では、Hugging Faceの主な機能とできることや実際の使い方、料金プラン、商用利用時の注意点まで分かりやすく解説します。実際にHugging Faceに公開されているコードを使って画像生成もしてみたので、ぜひチェックしてみてください。
目次
Hugging Faceとは?
公式サイト:Hugging Face
Hugging Faceは、AIや機械学習のモデルを共有・活用できる、世界最大級のオープンソースプラットフォームです。Hugging Faceは、フランスの起業家が2016年に米国で設立した会社で、当初はチャットボットの開発からスタートしました。
訓練済みのモデルを共有できるHugging Face Hubでは、数十万件以上の高品質なAIモデルや関連データセットにアクセスでき、公開されているモデルをベースにプロジェクトを立ち上げることも可能です。Hugging Face Hubを使えば、開発コストと工数を大幅に削減できるので、小規模チームでも本格的なAI開発に取り組めます。
Hugging Faceは日本語にも対応
Hugging Faceは日本語に対応しています。プラットフォーム上には日本語に特化したモデルも多数公開されていて、テキスト処理や翻訳、対話システムの構築に対応可能です。
たとえば、rinna株式会社、LINE、NTTといった日本企業が開発した日本語モデルが利用でき、日本語特有の文法や表現を考慮した高精度な処理が行えます。また、Hugging FaceのTransformersライブラリでは、日本語のチュートリアルも充実しているので、言語に不安がある場合でも使いやすいです。
Hugging Faceで使える主なモデル
Hugging Faceでは、自然言語、画像、音声、マルチモーダルの各分野に対応した高性能AIモデルが50万以上も登録されており、さまざまなタスクに簡単に活用できます。主要なカテゴリーとしては以下のようなモデルがあります。
| モデル | 用途・特徴 |
|---|---|
| BERT | テキスト分類や文書埋め込みなど多目的に利用可能 |
| RoBERTa | 文脈理解が強化され分類・QAにも有効 |
| DistilBERT | 軽量かつ高速、モバイルやQAにも好適 |
| XLNet | 双方向性と順序依存性に優れたBERT改良モデル |
| T5 | テキスト生成、要約、翻訳、質問応答などマルチタスク対応 |
| GPT-2 | 自然なテキスト生成に特化。プロンプト入力に対応 |
| BART | 長文やニュース記事の抽象的な要約に強み |
| MarianMT | 多言語翻訳に対応。英⇔日を含む多数の言語ペアをサポート |
| Stable Diffusion | テキストからの画像生成に対応。創作・デザイン用途に最適 |
| BLIP | 画像からの説明文(キャプション)自動生成が可能 |
| Whisper | 多言語音声認識モデル。高精度な文字起こしに対応 |
| Wav2Vec2 | 英語中心の音声認識モデル。学習効率も高い |
Hugging Faceの主な機能

Hugging Faceでは、AIモデルの検索や作成、API公開、ノーコード学習などAI開発に必要な機能がすべて揃っています。そのほかにも、コードが書けない人でもAIを試せる仕組みや、開発者同士で知識を共有できる環境が整っているため、AIの進化を支えるプラットフォームとなっています。
以下では、主な機能とできることを解説します。
- AIモデルの検索・利用(Models)
- AI学習データの検索・取得(Datasets)
- ノーコードで学習(AutoTrain)
- モデルのAPI化・公開(Inference API / Spaces)
- AIモデルの精度の評価(Evaluate)
- 開発者同士の情報共有(コミュニティ)
一つずつ詳しく見ていきましょう。
AIモデルの検索・利用(Models)
Modelsは、世界中の人が作ったAIを検索・利用できるAIモデルライブラリです。自然言語処理、画像認識、音声処理など幅広い分野の事前訓練済みモデルが50万以上公開されており、目的に応じて最適なAIを見つけ出せます。
使い方はとても簡単で、欲しいAIを検索して「Use this model」から使用方法を選択するだけです。Transformersライブラリを使用すれば、数行のコードで即座に実装でき、簡単にAI機能を自分のアプリケーションに組み込めます。
AI学習データの検索・取得(Datasets)
Datasetsは、AIに学習させるためのデータを簡単に探して使える機能です。テキスト分類、翻訳、質問応答、画像認識など、AI学習に使えるデータが用意されており、目的に合ったデータをすぐに見つけて活用できます。
例えば、感情分析AIを作りたい場合、従来は自分で大量のレビューを集めて整理する必要がありましたが、Datasetsを使えば、たった一行のコードで既存の感情ラベル付きデータをダウンロードできます。
自分で作ったデータセットをコミュニティに公開することもできるので、AIの研究や開発をユーザー同士で協力しながら進められる環境が構築されています。
ノーコードで学習(AutoTrain)
AutoTrainは、ノーコードで自分だけのAIモデルを作れる機能です。画面に沿ってデータをアップロードしてタスクを選択するだけで、自動的にAIが学習されてAIモデルが完成します。
たとえば「テキストの感情を判定したい」「画像をカテゴリーごとに分けたい」といった目的に合わせて簡単にAIを作成可能です。作ったモデルは、Hugging Faceのサイト上で公開したり、アプリやWebサービスにAPIとして組み込んだりして使えるので、実用レベルのAIを即座に完成させることができます。
モデルのAPI化・公開(Inference API / Spaces)
Inference API / Spacesは、開発したAIモデルをクラウドベースのAPIとして公開できる機能です。難しいサーバー設定などは一切不要で、モデルをアップロードするだけで、すぐに外部から使えるAPIが自動で用意されます。
Spacesでは、GradioやStreamlitといったツールを使って、対話型のAIアプリを簡単に作成できます。作成したアプリはそのままWeb上に公開できるため、研究成果のデモ、アイデアの共有、教育目的のツールなどの用途に幅広く活用可能です。
AIモデルの精度の評価(Evaluate)
Evaluateは、AIモデルがどれくらい正確に動くかを測れる機能です。タスクの種類に応じて、精度(accuracy)や再現率(recall)、F1スコア、BLEUスコアなどの指標を自動で計算し、モデルの性能を数値でわかりやすく示してくれます。
Evaluateでは、評価のルールが統一されているため、異なるモデル同士でも公平に比較できる点が大きな特徴です。また、独自の評価基準も設定可能で、プロジェクトに合わせて評価を行えます。
結果はグラフなどで見やすく表示されるので、モデルの良い点や改善すべき点を一目で把握でき、新たな開発・研究につなげられます。
開発者同士の情報共有(コミュニティ)
コミュニティは、Hugging Faceに登録している世界中のAI開発者が集まり、知識や経験を共有し合う場です。公式ブログで最新の研究成果や使い方が紹介されていたり、フォーラムを通してユーザー同士でアドバイス交換ができたりします。
また、GitHubと連携すれば、実際のコードを共有しながら開発に参加することも可能です。定期的にコンペやワークショップも開催されており、誰もが気軽に情報共有できる環境が整っています。
Hugging Faceの始め方
Hugging Faceを始めるためには、公式サイトにアクセスしてメールアドレス登録によるアカウントを作成します。
アカウント作成後は、プロフィール画像や自己紹介、GitHub連携などを設定できます(後からでもOK)。以上の設定のみで、誰でもすぐにHugging Faceの利用を開始できます。
アカウントを作成すると使える機能
- モデルの保存・共有:自作・取得したモデルを保存・公開できる
- Spacesの作成・公開:ノーコードでAIアプリを公開できる
- APIキーの取得:外部からモデルを呼び出すのに使える
- コミュニティ参加:コメントや質問で他ユーザーと交流できる
- データセットの公開・取得:学習用データを共有・活用できる
- チュートリアルやドキュメント:初心者向けのチュートリアルを見れる
Hugging Faceの使い方

ここでは、基本的なHugging Faceの使い方を画像付きで分かりやすく解説します。
Hugging Faceで公開されているモデルのダウンロード方法も手順に沿ってお伝えするので、利用時の参考にしてみてください。
モデルを探す方法
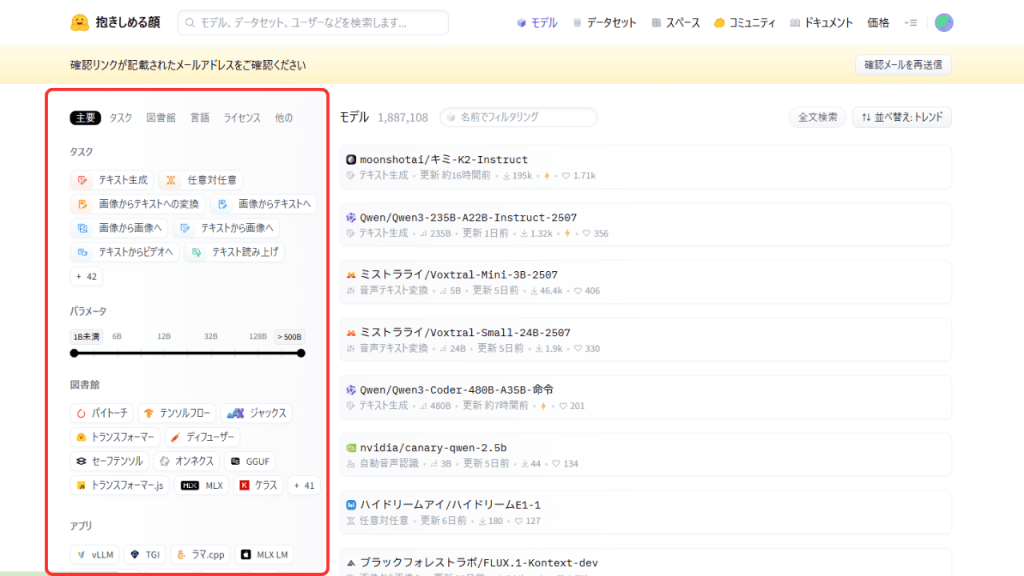
Hugging Faceでは、モデルを「タスク」や「フレームワーク」などの条件で簡単に絞り込んで探すことができます。
絞り込み検索をする場合は、メニューバーにある「モデル」からモデル一覧にアクセスし、画面左側のフィルター機能(画像の赤枠部分)を使うと、目的に合ったモデルを効率よく見つけられます。
また、画面上部の検索バーから「日本語」「BERT」「音声認識」などと入力して関連モデルを探すことも可能です。
絞り込みできる各項目の解説は以下の通りです。
- タスク:モデルが対応している機能(翻訳、感情分析、文字起こしなど)
- パラメータ:モデルのサイズや処理の重さ(軽量モデル〜大規模モデル)
- ライブラリ:AIモデルを動かすときに使うツール(Transformersなど)
- アプリ:AIモデルが使える形式(チャット形式、音声対応など)
- 推論プロバイダー:モデルを動かすクラウド環境やAPI基盤(TGI、VLLMなど)
気になるモデルが見つかったら、クリックして詳細ページを開きます。モデルの概要ページでは、説明、使用方法、API情報、デモなどを確認できます。
Hugging Faceのモデルをダウンロードする方法
Hugging Faceのモデルは、transformersライブラリを使って簡単にダウンロードして使うことができます。Hugging Faceのモデルのダウンロード方法は以下の通りです。
- transformersライブラリをインストール
- 使いたいモデル名を決める
- モデルをダウンロードして使う
手順に沿って順番にみていきましょう。
transformersライブラリをインストール
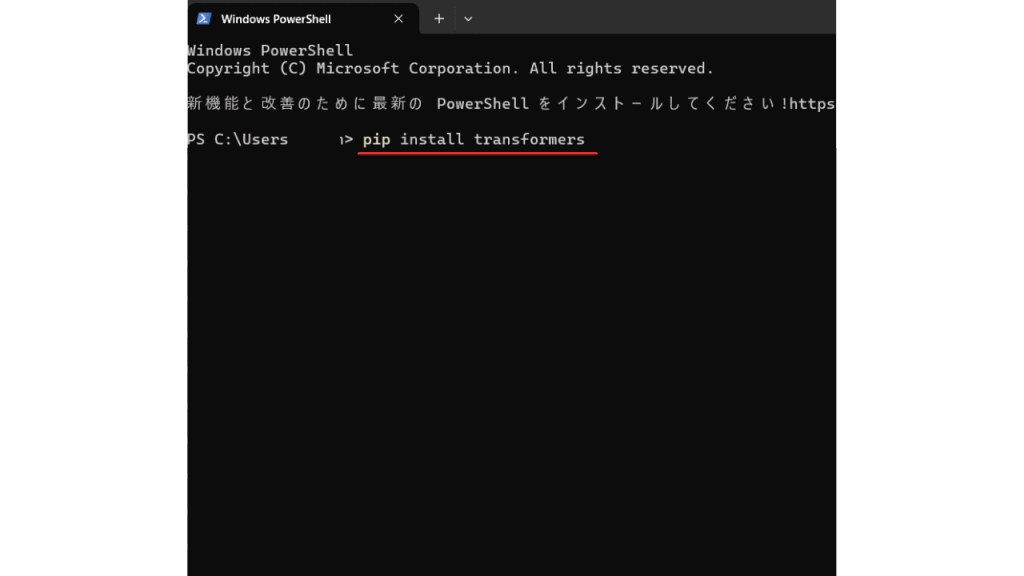
モデルを使うには、まずHugging Faceの主要ライブラリであるtransformersを、Pythonが動作している環境にインストールしましょう。
-
ローカル環境でPythonを使っている場合
pip install transformers -
Google Colabを使う場合
!pip install transformers -
Anacondaや仮想環境を使っている場合
conda activate myenv
pip install transformers
使いたいモデルを探す

Hugging Faceでは、AIモデルを使うときに「モデル名(ID)」を指定する必要があるので、使いたいモデルを探してモデル名を控えておきます。
モデルをダウンロードして使う
モデル名を控えたら、Python環境で以下のコードを実行します。※PowerShellを使用する場合は、以下のコードを入力する前に「python」と入力してPythonを起動させます。
from transformers import AutoTokenizer, AutoModel
model_name = "使いたいモデルID"
tokenizer = AutoTokenizer.from_pretrained("モデルID")
model = AutoModel.from_pretrained("モデルID")
※テキスト生成などを行う場合は AutoModel をAutoModelForCausalLM など用途に応じたモジュールに変更します
用途に応じた AutoModel の選び方(早見表)
- テキスト分類:AutoModelForSequenceClassification
- テキスト生成:AutoModelForCausalLM
- 翻訳:AutoModelForSeq2SeqLM
- 質問応答:AutoModelForQuestionAnswering
- 埋め込み取得:AutoModel
データセットをダウンロードする方法
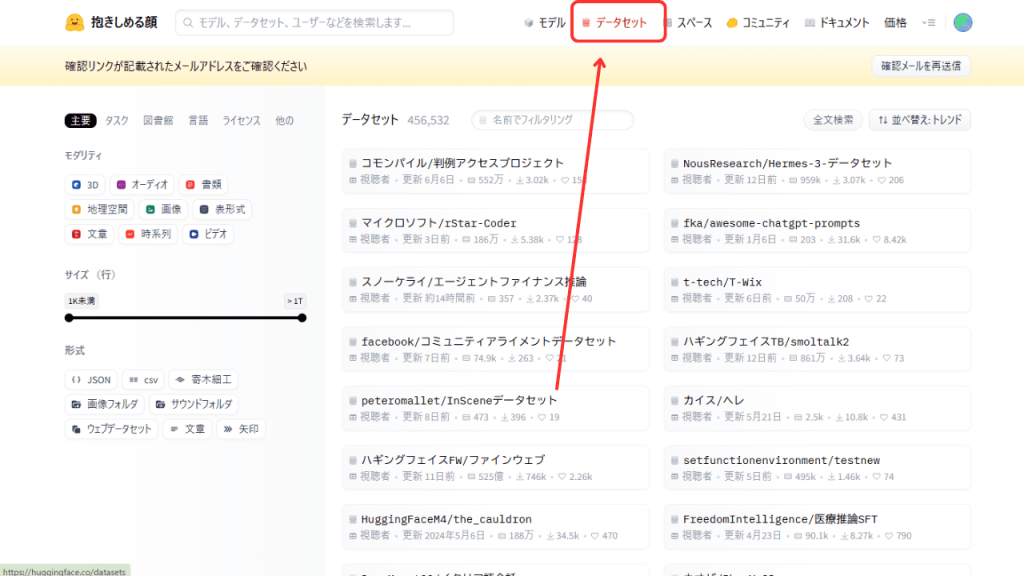
Hugging Faceでは、感情分析や翻訳などのAI学習に使える高品質なデータセットをダウンロードできます。ダウンロードをする際は、事前にdatasets ライブラリをインストールしておきましょう。
ローカル環境(PCや仮想環境)で実行する場合
pip install datasetsGoogle Colabで使う場合
!pip install datasets
次に、「データセット」から一覧にアクセスし、使用したいデータを決めたらクリックして詳細画面に行きます。詳細画面では「このデータセットを使用する(Use this dataset)」をクリックし、データセットの利用方法を選択しましょう。(基本的に「データセット」を選択すればOK)
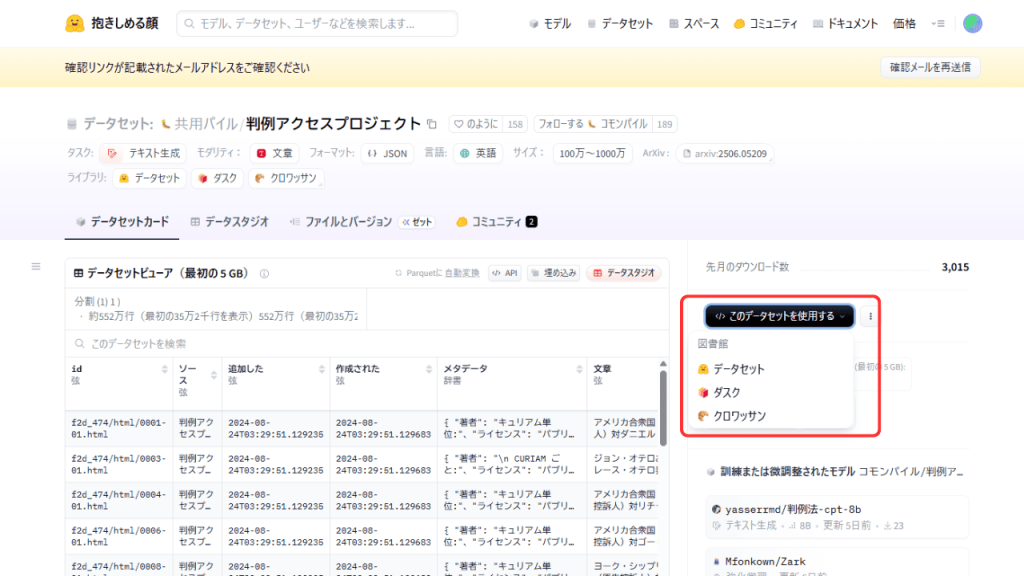
すると、Pythonでの使用例コードが表示されるので、自分のPython環境にそのままコピペして実行するだけでデータセットが自動でダウンロード・読み込みされます。
※PowerShellを利用する場合は、以下のコードを入力する前に「python」と入力してPythonを起動させます。
データセットのダウンロード完了後は、以下の手順でコードを入力すれば使用できるようになります。
-
データの中身を理解する
まずは学習に使うデータセットを読み込み、中身を確認します。
from datasets import load_dataset
データセット名を指定:dataset = load_dataset("データセット名")
分割情報(train/testなど)を確認:print(dataset)
各カラム(例:text, label)の構造を確認:print(dataset["train"].features)
データ1件目を表示:print(dataset["train"][0]) -
AIが読める形に整える(必要があれば)
トークナイザーを使ってテキストを数値化します。
from transformers import AutoTokenizer
トークナイザーを指定:tokenizer = AutoTokenizer.from_pretrained("モデル名")
トークナイズ関数:def tokenize(example):データ全体に適用:
return tokenizer(example["テキスト列名"], truncation=True, padding="max_length")
tokenized_dataset = dataset.map(tokenize, batched=True) -
モデルを準備する
テキスト分類タスクに合わせてモデルを準備します。
from transformers import AutoModelForSequenceClassification
モデル読み込み:model = AutoModelForSequenceClassification.from_pretrained("モデル名", num_labels=ラベル数) -
学習の設定を決める
ログ、バッチサイズ、保存先などを設定します。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
save_total_limit=1,
logging_dir="./logs",
logging_steps=10,
) -
実際に学習を開始する
Trainer クラスを使って学習を開始します。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"], # データによっては"validation"に変更
)
trainer.train()
デモ機能でモデルを試す方法
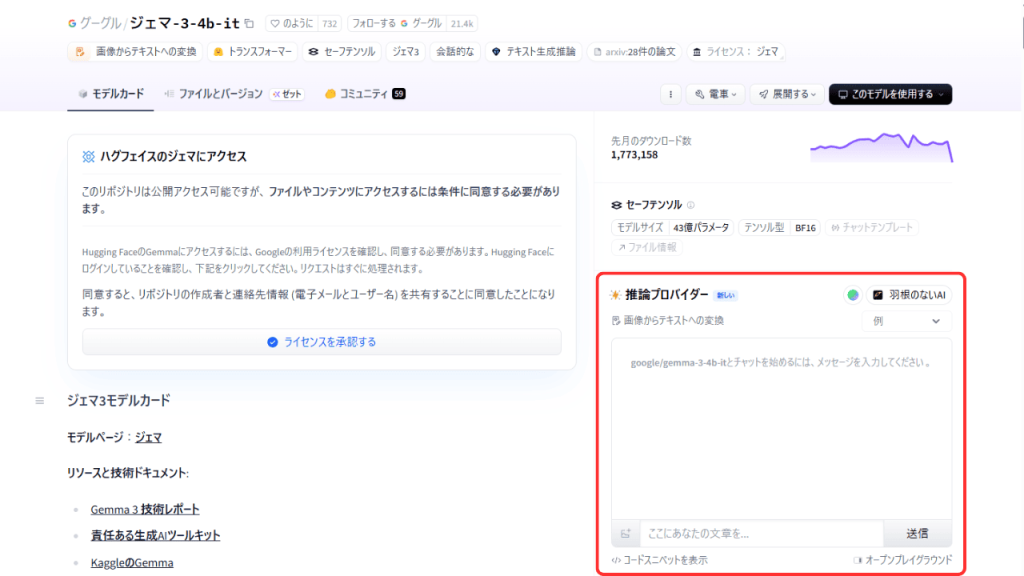
Hugging Faceでは、ブラウザ上で動作を試せるデモ機能がついています。
デモ機能は、モデル詳細ページにある「推論プロバイダー(Inference Providers)」から使えるので、各モデルごとの仕様に沿ってテキストや画像などを入力してみましょう。
「このモデルはどの推論プロバイダーによってもデプロイされていません」と書かれている場合は、Hugging Faceのクラウド上でデモ実行できない状態なので、Pythonなどのローカル環境にダウンロードして使う必要があります。
スペースを新規作成する方法
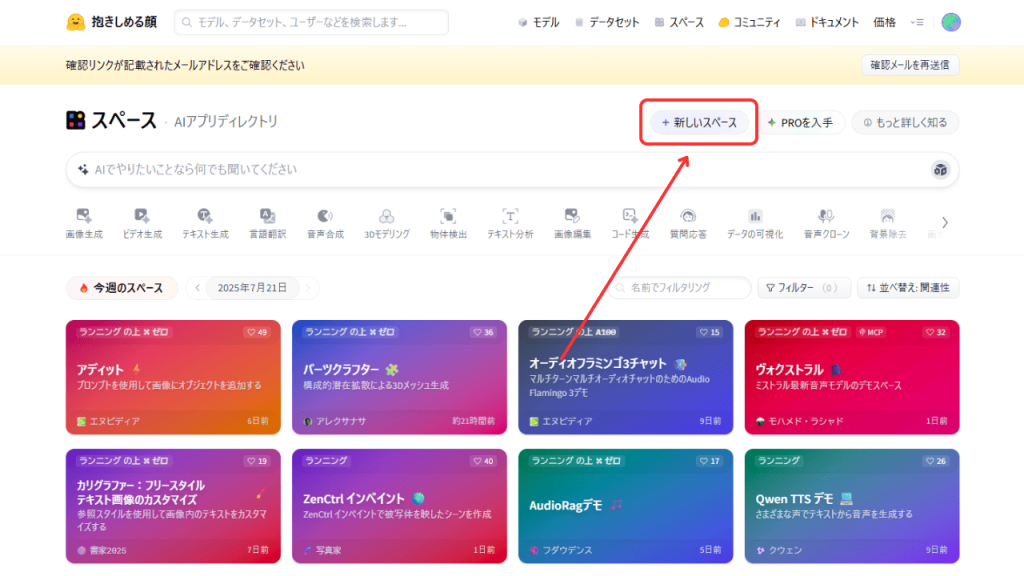
Hugging Faceの「Spaces」機能を使えば、GradioやStreamlit、自作AIアプリを簡単にWeb上で公開できます。
まずは、アプリを投稿するスペースを作ります。「スペース(Spaces)→新しいスペース(New Space)」を選択すると設定項目が表示されるので、以下の項目を入力して「Create Space」ボタンを押します。
- スペース名:公開URLにも使われる名前(英数字)
- Short description:アプリの説明
- License:MIT、Apache 2.0など(公開条件に合わせて選択)
- Select the Space SDK:使用フレームワークを選択(例:Gradio, Streamlit, Static, Docker)
- Space hardware:実行環境(無料:CPU basic など)
- 公開範囲:Public(誰でも見れる) / Private(自分と招待者のみ)
自作アプリをアップロードして公開・共有する方法
スペースでは、ブラウザ上で直接編集する方法と、Gitやターミナルからアップロードする方法の2通りでアプリを公開・共有できます。
ブラウザ上での操作であれば、Gitやターミナルを使う必要がないため、プログラミング初心者の方におすすめです。
ブラウザ上で直接コードを書く方法
ブラウザ上で直接コードを書く場合は、ヒント欄にある「あるいは、 ブラウザで直接 app.py ファイルを作成することもできます。」からコードエディタにアクセスできます。
エディタ画面では、以下の手順で操作を行います。
-
コードを入力
「編集」タブにアプリのコードを貼り付けます。 -
ファイルの公開設定を行う
エディタ下部にある公開設定セクションで以下のいずれかを選びます。
・直接コミットする:すぐに反映・公開される(通常はこちら)
・プルリクエストとして公開:後から承認して公開(チーム開発向け) -
ファイル名の確認
ファイル名がapp.pyになっていることを確認してください。
これは Hugging Face が実行対象と認識する重要な名前です(Gradio/Streamlit の場合)。 -
コミットメッセージの入力欄(説明欄)
画面下部にある「説明」欄にアプリの用途や注意点などを記載できます。
画像や動画の添付も可能です。 -
公開する
すべての設定が終わったら、「主要に新しいファイルをコミットする」ボタンを押します。
Hugging Face のスペースにアプリが公開され、誰でもアクセス可能な状態になります。
ターミナル操作(Git経由)でアップロードする方法
Hugging Face でスペースを作成すると、ターミナルで貼り付けるコードが表示されるので、以下の手順で操作を行いましょう。
-
Gitでスペースをクローン
Hugging Face が表示する以下のようなコマンドをコピーして実行します。
git clone https://huggingface.co/spaces/ユーザー名/スペース名 -
アプリファイルを作成
Python で以下のようなコードを保存します。
import gradio as gr
def greet(name):
return f"Hello {name}!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch() -
Gitの初期設定(初回のみ)
初めて使う場合は、Gitのユーザー情報を設定するために以下のコードを実行します。
git config --global user.name "あなたの名前"
git config --global user.email "あなたのメールアドレス" -
Hugging Faceにログイン(トークンの発行と設定)
Hugging Faceの設定ページからアクセストークンを生成し、ターミナル上でHugging Faceにログインします。
huggingface-cli login
ログインできたら、発行したトークンを入力し「Y」を選択します。 -
Gitでアップロード
スペースに戻り、「次にコミットしてプッシュします。」と書かれている下のコードを貼り付けて実行します。 -
公開URLでアプリ確認
Hugging Face のスペースページにアクセスすれば、自動で公開URLが生成されます。
Hugging Faceで公開されている画像生成モデルを試してみた!

今回は、Hugging Faceで公開されているStable Diffusion v1-4 Model Cardを使って、ローカルのターミナル(PowerShell)上で画像生成を実行してみました。
まずは、下準備として環境構築を行います。
必要なライブラリをインストール
pip install diffusers transformers accelerate safetensorsHugging Face にログイン
huggingface-cli login
Hugging Faceにログインできたら、モデルカードを参考にしながら以下の手順でコードを入力します。(float16非対応なCPU環境の場合の手順)
-
スクリプトを作成
notepad generate.py -
メモ帳に以下のコードを丸ごとコピペして保存
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
torch_dtype=torch.float32
)
pipe.to("cpu")
prompt = "A futuristic floating city above the clouds"
image = pipe(prompt, num_inference_steps=25, guidance_scale=7.5).images[0]
image.save("output.png")
print(" 画像生成完了!") -
実行して画像を生成
python generate.py
メモ帳に保存するスクリプトは、指定したテキスト(プロンプト)に基づいて画像を生成し、output.png という名前で保存するという内容です。
プロンプトの内容や保存ファイル名は自由に変更でき、例えば以下のように書き換えることも可能です。
prompt = "An anime-style girl standing under cherry blossoms"
image.save("sakura_girl.png")
実行して画像生成が始まると、下記画面のようにターミナル上で処理が開始されます。
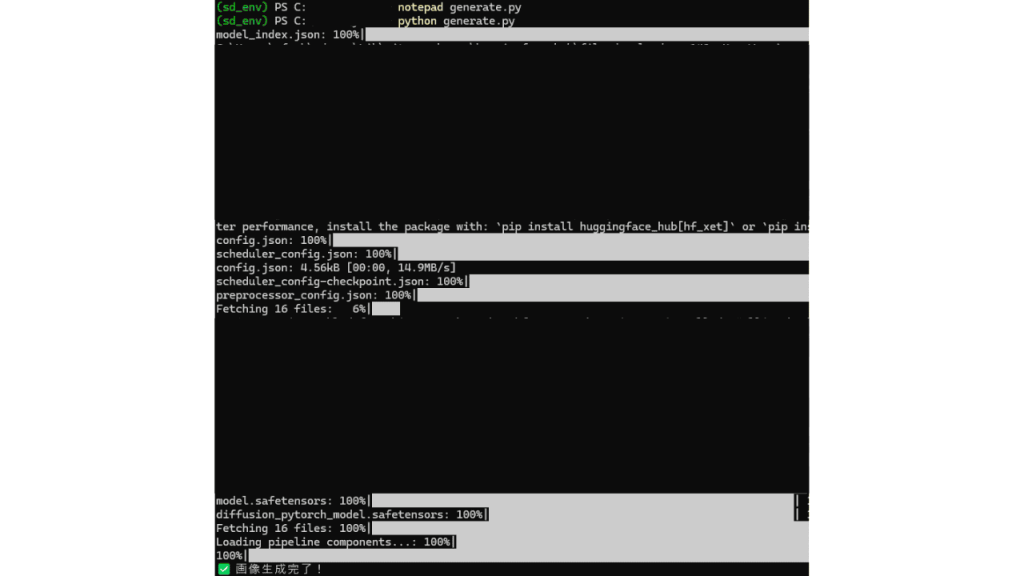
「画像生成完了!」という文字が出たら、「start output.png」と入力して画像を確認します。
実際に生成された画像はこちらです。

今回は、例に挙げた「An anime-style girl standing under cherry blossoms(アニメ風の女の子が桜の木の下に立っている様子)」というプロンプトを使用して画像生成をしてみました。桜の背景は完璧ですが、顔が上手く生成されませんでした。
Stable Diffusion v1-4は人物の細部や顔の描写が苦手な傾向があるため、表情やキャラクターのクオリティにこだわりたいときは、他のモデル(例えば waifu-diffusion や Anything-v4 など)を使うと良いかもしれません。
Hugging Faceを使ってみた感想
一度環境構築をすれば、テキストを変えるだけで画像が生成できるようになるので、使い方自体はシンプルだと感じました。
ただし、初期設定やライブラリのインストール、仮想環境の構築などが必要になるため、プログラミング初心者やターミナルが不慣れな人にとっては少しハードルが高いかもしれません。実行エラーが出ることもあったので、最初はある程度の試行錯誤が必要になるでしょう。
操作が難しい場面もありますが、ローカル環境でも無料で様々なAIを使える点は、Hugging Faceを使うメリットといえます。実際に試したように、実行したAIモデルに不備がある場合、他のAIモデルを何度でも切り替えて再実行できるため、試してみる価値は十分あると感じました。
Hugging Faceを使ってみた感想まとめ
- 初期設定に少し手間はかかりますが、環境が整えば使いやすい
- 実行中にエラーが出ることがあるため、不慣れな人は難しいケースも
- 様々なAIモデルを無料で使えるので試してみる価値はアリ
Hugging Faceの料金プラン
Hugging Faceは、基本無料で各機能を利用できます。無料プランでは、機械学習モデルのダウンロードや実行、公開されているコミュニティモデルの利用、小規模なデータセットの活用といった基本機能をすべて利用可能です。
以下の表では、各プランの詳細についてまとめました。
無料
モデル・データセット・アプリの無制限利用
チーム作成や共同管理もOKPRO Account
9ドル/月
ストレージ10倍、推論20倍
GPU待ち時間を短縮、自作アプリも公開可能Team
20ドル/月/1ユーザー
・SSO/SAML対応
・監査ログ/アクセス制御
・アクセス範囲の設定Enterprise
50ドル~/月/1ユーザー ※要相談
・チーム向けの機能搭載
・年間契約OK
・法務・コンプライアンス支援
・専任カスタマーサポート
有料プランを契約すると、より多くの計算リソースが使えたり、プライベートな開発環境を強化できたりと、本格的なプロジェクトでも対応できるようになります。個人利用なら無料で十分ですが、商用利用や複数人での開発には有料プランがおすすめです。
Hugging Faceは商用利用できる?

Hugging Faceは、使用するモデルやデータセットごとに商用利用の可否が異なります。中には「研究目的のみ利用可能」と明記されているモデルもあるので、商用利用する際は必ず各モデルページでライセンスを確認することが大切です。
利用規約にも、以下のように明示されています。
各モデルには独自のライセンスが設定されています。Apache 2.0、MIT、Creative Commonsなど様々なライセンスが混在しており、商用利用前には必ず個別のライセンス条件を確認する必要があります。一部のモデルは研究目的のみに限定されているものもあるため、特に注意深い確認が求められます。
企業やプロジェクトで使用する場合は、ライセンス違反により多額の損害賠償が発生する可能性もあるため、事前チェックや法務部門との連携を行うと良いでしょう。
Hugging Faceの安全性に関する規約
Hugging Faceでは、ユーザーの個人情報の不正アクセスや情報漏洩を防ぐ体制が整えられており、安全性は高いといえます。
Hugging Faceのプライバシーポリシーにも、以下のように明示されています。
お客様の個人情報のセキュリティは当社にとって重要です。当社は、適切な管理上、物理的、技術的保護手段の使用を含む、一般的に認められた業界標準に従い、個人情報を保護します。
ただし、Hugging Faceにアップロードしたモデルやデータセットは、初期設定では「公開状態」になっているため、個人情報が公開されないように匿名化などをしておきましょう。また、自分のパソコンやアカウントのパスワード管理・ウイルス対策など、利用環境のセキュリティを保つことも大切です。
Hugging Faceの注意点

Hugging Faceを利用する際には以下の3つの注意点を押さえておくと良いです。
- AIモデルの品質が大丈夫か確認する
- ライセンスは必ず確認しておく
- 依存ライブラリのアップデートに注意する
それぞれの注意点について詳しく解説します。
AIモデルの品質を確認する
Hugging Faceで公開されているAIモデルは、作成者によって精度や内容に差があります。しっかりと確認しないと、学習データに含まれる考え方や偏った表現が、そのまま出力結果に反映されてしまうため注意が必要です。
たとえば、性別や人種、文化について不適切な表現が出る可能性があります。意図しない出力によるトラブルを防ぐためにも、活用前に出力内容を確認し、欲しい結果が得られるか検証してから導入しましょう。
ライセンスは必ず確認しておく
Hugging Faceを利用する際は、データセットやモデルのライセンスを必ず確認しましょう。商用利用だけでなく、改変・再配布に関する制限が設けられている場合もあるので、ライセンス違反をしないように注意が必要です。
ライセンスは、各モデルの詳細ページの名前の下にあるタグで確認できます。「ライセンス:○○」という形でタグが付いているので、表記をよく読み、条件を満たしているかをしっかり確認しましょう。
使用しているライブラリの更新に注意する
Hugging FaceのTransformersやDiffusersなどのライブラリは、頻繁に新しいバージョンに更新されます。更新に伴い、エラーが起きるケースがあるので、使っているバージョンを決めて固定したり、更新前にテスト用の環境で動作を試したりすると良いです。
また、新しいバージョンでは、バグが修正されている場合もあるため、アップデートの内容を定期的にチェックし、必要に応じて更新するようにしましょう。
Hugging Faceまとめ
Hugging Faceは、AIや機械学習のモデルやデータを誰でも自由に使えるオープンソースプラットフォームです。自然言語処理や画像生成などの高度なタスクも、ノーコードで簡単に試せるのが特徴です。
無料プランでも多くの機能が利用でき、小規模な開発や学習には十分対応可能です。ただし、モデルごとにライセンスが異なるため、商用利用前には確認が必要です。
導入時に多少の準備は必要ですが、一度整えれば直感的に使えます。50万件以上のモデルを自由に試せるので、アイデアの検証やプロトタイプづくりにぜひ活用してみてください。
RANKING ランキング
- WEEKLY
- MONTHLY
UPDATE 更新情報
- ALL
- ARTICLE
- MOVIE
- FEATURE
- DOCUMENT
-
ARTICLE
2019/03/26( 更新)
家事代行サービスを開業して集客を成功させる方法を解説!成果を出すWeb活用戦略とは
企業経営業種別
- 集客
-
NEW ARTICLE
2026/03/16
【2026年最新】リスティング広告に使える補助金・助成金まとめ
広告広告運用
- リスティング広告
-
NEW ARTICLE
2026/03/12( 更新)
リスティング広告に向いている業種・商材の特徴と具体例【チェックリストあり】
広告広告運用
- リスティング広告
-
ARTICLE
2026/02/04( 更新)
リスティング広告運用代行会社の選び方!確認すべきポイントや代行費用相場を解説
広告広告運用
- リスティング広告