
構造化データとは?非構造化データとの違いやマークアップ方法を解説

構造化データとは、検索エンジンにサイト内のページ内容をわかりやすく伝えるデータ形式のことです。間接的なSEO対策になるので、Webサイトを運営するなら知っておきたい手法です。
本記事では、構造化データと非構造化データの違いや、構造化データの種類、設定するメリット、マークアップ方法など抑えておきたい基礎知識をわかりやすく解説しています。廃止された構造化データ一覧や、エラー確認のテストツールも紹介しているので、ぜひ参考にしてください。
目次
構造化データとは?

構造化データとは、Webサイトのページ内容を検索エンジンにわかりやすく伝えるためのデータ形式(ソースコード)です。Excelの「列」や「行」のような概念を持ち、どんな情報があるのか組み立てて構造化しています。
リッチリザレクトという、検索結果に補足として情報を表示させたいときなどに、構造化データに記述を追加します。
構造化データの定義と特徴
構造化データをより細かく定期づけるなら、セマンティックWebを実現するためにHTMLの情報をより正確に理解できるようにしたものです。セマンティックは「意味」をのものを指し、記述される個々の情報に意味づけし、情報をより構造的にする手法です。
特徴としては、ソフトウェアのソースコード(文字列)を、人が認識するような細かいデータのとして上撮れます。例えば、名前・生年月日・電話番号などを含む構造化データを、顧客数や地域などのデータに紐づけられます。
属性の数の測定や、数値データに対しての演算も可能です。まさに、物事を定義したうえで、要素の関係を整理(構造化)しています。
構造化と非構造化データの違い
構造化データと非構造化データの違いは「規則性にのっとった組み立てがあるか」です。非構造化データは、区切りのないテキスト・画像・動画・音声など、規則性がありません。データを見ただけだと、どれに紐づけて良いのかもわかりづらいです。
構造化データの要素4種類

構造化データは、以下で紹介する4つの要素で構成されています。その中でも「シンタックス」と「ボキャブラリー」だけは最低限覚えておくと良いです。
シンタックス
シンクタックスは、構造化マークアップを行う仕様(記述方法)を指します。Googleがサポートしている形式は「JSON-LD(推奨)」「microdata」「RDFa(RDFa Lite)」の3つです。
もともとはmicrodataが主流でしたが、コードがシンプル・CMSでも使用可能なことから最近では「JSON-LD」がメインとなっています。
ボキャブラリー
ボキャブラリーは、構造化データの定義のことです。人物で言うなら、name(名前)やaddress(住所)などが当てはまります。
Googleでは「schema.org」のボキャブラリー定義に則っています。なお、過去に利用できた「data-vocabulary」は2024年5月時点でサポートが終了しています。
タイプ
タイプは構造化データの種類を指し、「@type」と言われています。ブログ記事やプロフィールページ、パンくずリストやよくある質問など、どういう構造化なのかを示しています。この種類は、リッチリザルトを設定する際に使用します。
プロパティと値
プロパティと値は、構造化データの情報項目です。「必須プロパティ」と「推奨プロパティ」の2つが存在し、前者は構造化データを機能させるうえで必ず情報入力しないといけません。
推奨プロパティは任意ですが、記述が多いとリッチリザレクトの表示確率が上がります。できる限り入力しておきましょう。
構造化データの主なメリット

構造化データは、検索エンジン関係で以下の2つのメリットがあります。100%効果が出るわけではありませんが、やっておいて損はないものです。ぜひWebサイト運営に活かしましょう。
検索エンジンに対するコンテンツの理解促進
構造化データは、検索エンジンにWebページの中身をくわしく伝えるものです。テキストや画像の意味を正しく理解することで、コンテンツの質が良いを評価してもらいやすいです。
ユーザーにとって答えとなる内容であれば、順位も上がりやすいです。このように、間接的ではありますがSEOとしての効果が期待できます。
リッチリザルトでクリック率向上
リッチリザルトは、検索結果のタイトルリンク以外に、必要な追加情報を表示するものです。「FAQ」「サイトリンク」「店舗情報」などのページの中身が少しだけ検索結果に表示されるので、ユーザーの興味を引きます。
結果、ユーザーが求める情報との相違がなく、クリック率が向上しやすくなります。
構造化データをHTMLに直接マークアップする方法

構造化データをHTMLに直接マークアップする場合、大きく分けると3つの方法・仕様があります。先述したシンタックスです。
ここではGoogleがサポートしているシンタックス、「JSON-LD」「microdata」「RDFa(RDFa Lite)」の具体的な記述例を紹介していきます。
JSON-LDでの構造化データマークアップ
JSON-LDは、headタグ要素内が一般的でHTML内のどこでも記述が可能です。データを1箇所にまとめられる・記述量が少ないので、シンプルでわかりやすい点が特徴です。
【JSON-LDの記述例】
<script type="application/ld+json">
{
"@context" : "http://schema.org/",
"@type":"Thing",
"name":"商品名",
"description":"商品の説明",
"image":"画像のURL"
}
</script>
@contextで規格の定義、@typeでタイプが指定されます。今回はschema.orgのボキャブラリー定義を使用しています。
コンテンツの変更の際には、JSON-LDの調整も必須です。忘れないように注意しましょう。
microdataでの構造化データマークアップ
Microdataは、headタグ要素以外でもmetaやlink要素を使って記述できます。また、精度の高いHTML5 の構文に違反しないことがメリットです。
主に「itemscope」「itemtype」「itemprop」がプロパティとして使われています。
【microdataの記述例】
<div itemscope>
<p>私の名前は<span itemprop="name">新宿花子</span>です。</p>
</div>
1行目の、divの開始タグ内にitemscope属性がついています。
Microdataのメタデータの本体は、ルールとしてプロパティ名である「name」、値の「新宿花子」がペアです。このマークアップによって、新宿花子という文字列がnameであることを検索エンジンに伝えられます。
なお、終了タグの/divの間には、itempropでのプロパティが記述されています。itemtype は次のように使われます。
<section itemscope itemtype="http://schema.org/Person" >上記の場合、人物の情報を定義づける役割が果たされます。
RDFa Liteでの構造化データマークアップ
RDFaもRDFa Liteも機能としてはほぼ同じです。RDFaが複雑なのに対し、もっと使いやすく簡素化したものが「RDFa Lite」となります。
HTMLのソースコードで該当する箇所の近くに、構造化データを記述する点はMicrodata同様です。W3Cによって規格化された形式で、「HTML5」や「XHTML」など幅広い言語で使用できます。
【RDFa Liteの記述例】
<div vocab="http://schema.org/" typeof="Corporation" >
<span property="name">株式会社●●●</span>
<span property="address" typeof="PostalAddress">
<span property="postalCode">160-0023</span>
<span property="addressRegion">東京都</span>
<span property="addressLocality">新宿区</span>
<span property="streetAddress">新宿●-▲-■ 〇〇ビルディング△階</span>
</div>
各属性については、vocabは規格の定義、タイプ名はtypeofを用います。上記の記述例の場合は、指定は会社を示すCorporation、郵便番号と顧客バーコードデータを示すPostalAddressを使用。そして、propertyには該当する内容が入ります。
構造化データは自動マークアップも可能

「データハイライター」という、Googleが用意したツールを使えば、構造化データの自動マークアップができます。これはサーチコンソールの機能の1つです。
エンジニアでなくてもマークアップが可能です。ただし、クローラーが回ってきたページにのみ使用可能なうえ、サポートされているデータタイプに制限があるので注意してください。
データーハイライトの使い方
- 使い方1:データハイライターにアクセス
- 使い方2:URLとページの種類を選択
- 使い方3:類似の構造ページを自動抽出
- 使い方4:コンテンツ要素をセット
- 使い方5:セットされたページのステータスや詳細を確認
ページの種類がマッチしていないと、意図しない構造ページが抽出されてしまいます。必ず確認しておきましょう。
使用できなくなった構造化データ一覧

Google検索でサポートされる構造化データは、定期的に見直しや廃止が行われています。過去には活用されていたものでも、現在では無効化されたり、リッチリザルトに反映されなくなっていたりするケースもあります。知らずに古いマークアップを残していると、意図した検索表示につながらない恐れもあるため注意が必要です。
ここでは、2025年7月現在でGoogleがサポートしていない、または使用を推奨していない構造化データの例を一覧にまとめました。対象の構造化データを使用している場合は、最新の仕様に沿って内容を見直しましょう。
| 構造化データ名 | 状態 | 廃止時期 | 備考 |
|---|---|---|---|
| Breadcrumb(data-vocabulary.org形式) | 廃止 | 2020年1月 | schema.org形式への移行が必要 |
| WebPage | 非推奨 | 2021年頃 | Schema.org上では有効だが、リッチリザルトにならない |
| Website | 廃止 | 2021年頃 | SearchBox表示用のマークアップが不要に |
| SocialProfile | 廃止 | 2022年 | ナレッジパネル表示には非対応 |
| COVID-19 SpecialAnnouncement | 廃止予定 | 2023年 | パンデミック対応終了により削除見込み |
| Speakable | 非推奨 | 2023年 | Googleニュース対応限定。ほぼ機能停止状態 |
構造化データは、Googleが提供する機能(リッチリザルトやナレッジパネルなど)と連携させるための重要な要素です。しかし、全ての構造化データが今も有効というわけではなく、Googleの仕様変更によりサポート対象外となったものも少なくありません。
とくに、パンくずリストやWebページ情報、SNSプロフィールなどに使われていた一部の構造化データは、現在では検索結果への反映が行われなくなっています。使い続けてもSEO効果が見込めません。
廃止・非推奨のものは他の構造化データに置き換える
廃止・非推奨になった構造化データは、記述自体はできますが意味を成しません。そのため、他の構造化データに置き換える対応をしたほうが良いでしょう。たとえば、Webサイトでよく使用されていた「Website」や「WebPage」は、以下のようなものに置き換えられます。
| コンテンツ内容 | 置き換える構造化データ |
|---|---|
| 会社概要など | Organization |
| 商品詳細 | Product |
| ブログ記事 | BlogPosting、Article |
| 使い方説明 | HowTo |
| よくある質問ページ | FAQPage |
| パンくずリスト | BreadcrumbList |
SEO施策として意味を持たせるには、用途に応じた構造化データに置き換えることが重要です。コンテンツの種類ごとに適した構造化データを活用することで、Googleへの情報伝達精度が高まり、検索結果での視認性向上につながります。
▶参照:Google 検索がサポートする構造化データ マークアップ
構造化データにエラーがないか確認できるテストツール
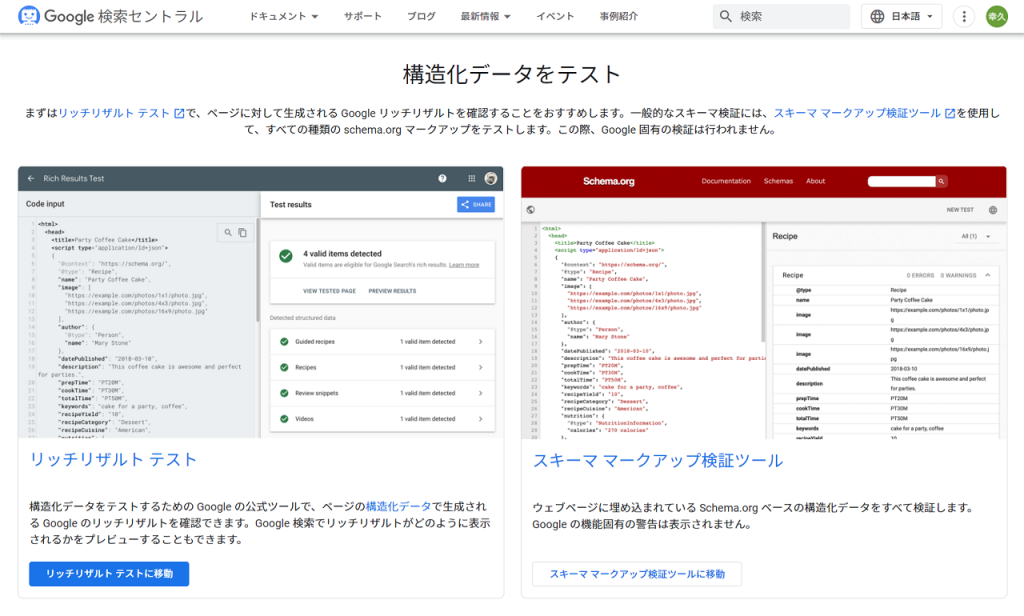
構造化データをマークアップした際に、検索エンジンが認識しているかどうかはテストツールを使えば確認できます。エラーが一目でわかるうえ、手軽で使いやすいものを2つ紹介します。
リッチリザルトテスト
「リッチリザルトテスト」はGoogleが提供しているツールです。URLもしくはコードを入力すると、エラーが発生している箇所が表示されます。
レンダリング後の HTML コードの確認や、プレビュー表示や加えてモバイル・PC 両方のユーザーを識別したうえでの検証を可能にするなど機能の充実しています。
Schema Markup Validator
「Schema Markup Validator」は、schema.orgが提供する構造化データ テストツールの後継です。使い方はリッチリザルトテストと同様に、URLもしくはコードを入力するだけです。
schema.org が定義しているすべての構造化データの検証が可能です。プロパティの値の形式は問われません。検証対象は、あくまで文法的に正しいか否かです。
構造化データに関する疑問や課題

構造化データは100%活用できるものかと言われれば微妙です。そのため、疑問や課題の声が多数上がっています。その中でも、デメリットに近いものや、AI技術に関しての課題を簡単にまとめました。
リッチリザレクトは原則1ページ目の表示
構造化データをマークアップしても必ずリッチリザレクトが表示されるわけではありません。原則、検索結果の1ページ目かつ上位表示されているものが優先されます。
そのため、ページ自体のSEO対策をしっかりして、検索順位を上げることが重要です。
非構造化データと比べると用途が限定的
2024年5月時点で、構造化データの用途は限定されています。データの整理や、リッチリザレクトの表示がメインです。
非構造化データの場合は構造化されておらず、さまざまな角度から分析・活用が可能です。自由度の高さから言っても、活用するなら非構造化データのほうがやりやすいと言われているほどです。
機械学習やAIに活用する際のデータ量が課題
データが整理されている点においては、機械学習やAIに活用しやすいです。しかし、総務省公表の「平成25年版情報通信白書」によると、企業が作成するデータの8割ほどは非構造化データ。
構造化データの数が少なく、上手く最新技術に活用できていないことが今後の課題です。非構造化データを構造化データのように上手く管理できるなら、ガラリとWebに関する技術が変わっていくはずです。
Googleのエンジニアが語った構造化データの未来

構造化データ関連の機能開発を担当しているソフトウェアエンジニアの Ryan Levering(ライアン・レブリング)氏が、自身がゲストで招かれたポッドキャストで配信されている「Search Off The Record」のエピソード 35で長期的に考える構造化データの展望を次のように語っていました。
内部グラフの解釈に構造化データが本当に重要な役割を果たすだろう。機械学習がさらに関わってくると思う。ページのすべての情報を構造化データで必ず伝えるというよりも、構造化データで特定したルートを通してもっと多くのデータを調整していきたい。
内部グラフの解釈に構造化データが本当に重要な役割を果たすだろう。機械学習がさらに関わってくると思う。ページのすべての情報を構造化データで必ず伝えるというよりも、構造化データで特定したルートを通してもっと多くのデータを調整していきたい。
引用元:Search Off the Record: Structured data: What’s it all about?
さらには、人間を介さず、CMS やプラグインが必要な構造化データを自動的に実装するのが理想だとも考えているようです。
中期的には「構造化データを使ったより多くの機能の提供」「視覚的な機能にとらわれないページの理解」「多くの機能で構造化データを普遍的に使う」といった考えも明らかにしています。
そう遠くない将来、Googleは新たな仕組みを提供してくれると期待できます。構造化データがどのように進化していくか、今後も要チェックです。
RANKING ランキング
- WEEKLY
- MONTHLY
UPDATE 更新情報
- ALL
- ARTICLE
- MOVIE
- FEATURE
- DOCUMENT